Living in Emacs
Table of Contents
- Managing emacs packages with use-package and a shell script.
- Documentation in Linux linux
- Advising a function
- Literate Programming
- Elisp, Bitlbee, ERC
- Dired and wdired.
- Presentations with reveal.js
- Gnus for mail, lists and RSS.
- Org mode spreadsheet
-
eshelland TRAMP -
org-time-stamp -
org-table-convert-region - Regex builder and lisp-regexes
Some tips on using and setting up emacs, particularly in linux.
Managing emacs packages with use-package and a shell script.
One of the things I liked the most about emacs 24 was the inclusion of a package manager. I quickly found myself installing a bunch of cool packages which made my emacs experience even more awesome than it was before – and it was really easy! Then I had to go work on another machine, and I realised my folly.
Of course, my emacs configs are in git. But my collection of
interactively-installed packages weren't. So I stopped installing
packages using M-x list-packages, and started keeping a file full
of lines like (package-install 'multiple-cursors). When I came to
a new machine, I could just eval that file, and all would be well.
Except that some packages are best installed from ELPA, some from
marmalade, some from MELPA, and some from MELPA Stable. And if you
want to upgrade something in MELPA Stable, you need to be sure that
your emacs doesn't currently have access to MELPA (or you'll
accidentally get a bleeding edge version of the package). And if you
want to upgrade org-mode, then you have to do it before any
org-libraries have loaded. Which is tricky for me, because I keep my
init files in org…
Around about this time, I saw this Sachachua / John Wigley interview
which covers Wigley's excellent use-package package. You can use
use-package along side the repositories (and Chua does this) but the
way Wigley uses it is different. He doesn't tell us how he aquires
the packages he uses, but he keeps them in his home directory, and
uses use-package to load them as needed. This way he has a fast
startup time, a uniform set of config files, and full knowledge
about what his emacs is actually doing. I've copied this idea
verbatim, and my emacs configs are now full of lines like:
(use-package evil-org :diminish evil-org-mode :load-path "~/elisp/evil-org-mode")
But that doesn't solve the problem of where I get my packages from.
Finally, I decided to avoid the confusion of the various
package-archives and get my packages from their sources. To avoid
the problem of upgrading org-mode while org was running, I've
decided to keep my emacs-package-management outside of emacs. The
result is this handy shell script (tested with bash, dash, nixos and
slackware). It contains functions for checking git repos (doing a
fresh clone if needs be, or just a git-pull otherwise), downloading
tarball distributions of packages, running configure and make if
needs be, or just downloading a single .el file from a web server
somewhere. The result is that running the script on a fresh machine
will download all the packages I usually use. Otherwise, running the
script will upgrade all the packages I keep at the bleeding edge
(the git and hg repos). If I want to switch to a new version of a
package for which I downloaded a tarballed release, then I have to
change the version number manually.
Perhaps I've just re-invented a rubbish version of el-get, but right now I'm not sure I care. My script is pretty simple, and I think I understand what it does. When things inevitably break, I think I've got a pretty good chance of knowing what's going on and being able to fix them.
To give a flavour of how the script works, there are a bunch of functions that look like this:
# Check the directory, and either update the contents with hg, or # clone a fresh one. Optionally "make" depending on $3. getWithHg () ( if [ -d "$1" ] ; then echo "updating $1" ; ( cd "$1" && hg pull ) ; else echo "cloning $1" ; hg clone "$2" ; fi ; if [ ! -z "$3" ] ; then echo "making $1" ; ( cd "$1" && make ) ; fi ) # Check the directory, and either update the contents with hg, or # clone a fresh one. Then make it. getWithHgAndMake () ( getWithHg $1 $2 "yes, make this please" )
…and then there's a long list of calls to those functions, to get the various packages I use:
... getWithGit "bbdb-vcard" "https://github.com/vgeddes/bbdb-vcard.git" getWithGit "color-theme-approximate" "https://github.com/tungd/color-theme-approximate" getWithHttp "emacsed.el" "http://aon.iki.fi/files/emacsed/emacsed.el" getAndMakeTarBallWithHttp "ess-15.03-1" "http://ess.r-project.org/downloads/ess/ess-15.03-1.tgz" getWithGit "gnorb" "https://github.com/girzel/gnorb.git" getWithHttp "gnus-notify.el" "http://www.emacswiki.org/emacs/download/gnus-notify.el" ...
You can read the full thing here.
Documentation in Linux linux
Quite a lot of the GNU/Linux ecology is beautifully documented.
Unforunately many people seem unaware of the wonderful manuals and
info pages on their machines, and end up hunting down the answers to
simple questions in reams of blog posts and stackoverflow questions.
Even worse, users of debian and debian-based systems often don't
have their documentation installed for ideological reasons. If you
can't figure out how to install the docs on your distro-of-choice, I
tarred up the /usr/info/ dir from my slackware box, and put it
here. Every glibc function is documented. There's a guide on how to
write bash programs. There are docs for every installed utility from
acct to zmore.
I highly recommend learning to use the GNU info system, especially
if you're an emacs user. Emacs users can get started by hitting
C-h i h, while console-users can type "info info".
A lot of emacs packages provide their own info files. If, like me, you tend to install emacs packages in your home directory (rather than site-wide) it's easy for that documentation to get lost. Here's how I avoid that.
ETA: Vim users can use plugins such as this or this. I don't yet know if they can do the browsable dir file consolidation that the emacs info browser does.
Advising a function
Advice is a dangerously powerful programming tool. The idea is that
you're using some library, and it almost does what you want it to
do… Except for some function f, which doesn't quite behave the
way you'd like. So you "advise" f to behave differently. You write
some other function g, and you tell the runtime that every time
anything (including library internals) tries to call f, it should
call g first (or call g after f, or instead of f). This
allows the programmer to reach into the guts of some previously
encapsulated library, and mess around with them.
This is dangerous, because it can make debugging extremely
difficult. It means that the function you think you're calling may
not be the function you're actually calling. If you're working in a
dynamic language, then advice can usually be added and removed at
runtime, so the behaviour of a simple sub-program like (plus 2 2)
could change in the middle of your debugging session. Since advice
is so dangerous, it should only be used in situations when we can't
find any other solution.
I think I found such a situation in my emacs config today.
Git-gutter-plus is a handy gadget which persistently shows which
lines in the current file differ from the repo, and lets you commit
changes directly. Irritatingly, it can cause a big slowdown if it's
enabled on very large files. Such as some of my org-files, for
example. For this reason I want to enable global-git-gutter+-mode,
but disable it for certain files and directories. I don't want to
just enable it for certain modes – since I need it disabled for
some of my (large) org files, and I want it enabled for others. I
can't use file-local or directory-local variables to solve the
problem, because global-git-gutter+-mode adds
git=gutter+-turn-on to the file load and revert hooks.
The solution seems to be to advise the internal functions
git=gutter+-turn-on and git-gutter+-reenable-buffers.
The key part of the config is this:
(defvar-local gds/git-gutter+-okp t "Is it ok to enable `git-gutter+-mode' on this file?") (advice-add 'git-gutter+-turn-on :before-while (lambda () gds/git-gutter+-okp)) (advice-add 'git-gutter+-reenable-buffers :before-while (lambda () gds/git-gutter+-okp))
We create a new buffer-local variable gds/git-gutter+-okp, which
is true by default. The idea is that whenever this is true, it's ok
to use git-gutter+-mode. If we want some file to not use
git-gutter+-mode, then we set this variable to nil.
The line:
(advice-add 'git-gutter+-turn-on :before-while (lambda () gds/git-gutter+-okp))
…adds advice to the git-gutter+-turn-on function. The advice is
added :before-while the function, which means that the function
will be called if and only if the advice returns true. The advice we
add is the (lambda () gds/git-gutter+-okp), which does exactly
what we want.
This uses the new advice system from emacs 24.4. If you're only familiar with the old defadvice stuff, you should definitely check it out.
The upshot is that now I can set gds/git-gutter+-okp to nil in
the file- or directory-local variables of any file that would
otherwise cause problems.
My whole git-gutter+ config now looks like this:
(use-package git-gutter+ :load-path "~/elisp/git-gutter-plus" :defer 5 :diminish git-gutter+-mode :commands global-git-gutter+-mode :bind (("C-x C" . git-gutter+-stage-and-commit) ("C-x c" . git-gutter+-commit) ("C-x t" . git-gutter+-stage-hunks)) :config (defvar-local gds/git-gutter+-okp t "Is it ok to enable `git-gutter+-mode' on this file?") (advice-add 'git-gutter+-turn-on :before-while (lambda () gds/git-gutter+-okp)) (advice-add 'git-gutter+-reenable-buffers :before-while (lambda () gds/git-gutter+-okp)) (global-git-gutter+-mode))
Literate Programming
I once heard Don Knuth say that the name structured programming was genius. By calling this new style of programming "structured", it implied that what everyone else was doing was "unstructured" – and no-one wants to be accused of that. Some people grumbled at the percieved slight, but the name worked. We now all write structured programs. This effect inspired him to name his new programming style literate programming.
Literate programming means writing your code and documentation at the same time. Rather than writing "a program" (which may contain comments) you write an essay which describes a program (and will contain code fragments). And you do so in such a way that it can be easily run on a computer, or printed as a book or article. Knuth produced tools to support this workflow, and it could be argued that this way of thinking about things eventually led to the likes of Doxygen, Javadocs and Haddock tools commonly used today.
However, the real successor to Knuth's tools, is surely org mode. Org is an excellent typesetting language, which can generate HTML, pretty-printed ASCII, PDFs, and slideshows of various descriptions. For example, this website is generated from a set of org files. Org also comes with babel, which allows us to embed code (in any language) in org files. That code can be pretty-printed as a part of the export process, or it can be run on a computer. My emacs configuration is well over 2000 lines of code written this way.
Of course, org is massively configurable. For example, my emacs configuration contains some code which necessarilly involves personal information which I'd rather not see on the net. When I ask emacs to publish my configs, emacs first redacts all personal information from them. You can read the (redacted) code which does this here.
Elisp, Bitlbee, ERC
So, someone on IRC says "Today at 16:53:20 GMT, it'll be 1400000000 in Unix time", and your first thought is "I wonder if my emacs can automatically post a celebratory tweet at exactly the right time?"
Of course it can.
(run-at-time "17:53:20" nil (lambda () (switch-to-buffer "#twitter") (erc-send-message "Happy #unix 1400000000! (this tweet brought to you by #emacs run-at-time and #bitlbee)")))
…or at least I hope that's right. I'm writing this before 16:53:20
GMT, so I haven't actually seen it work yet. Even if it does work as
I expect, I think run-at-time will only bother parsing the time
to the nearest minute anyway. But hopefully that should be close
enough for twitter.
For this to work, you have to be using ERC to talk to bitlbee, and
your twitter channel has to be called #twitter.
Update: It worked.
Dired and wdired.
Oh no! I have accidentally created a bunch of files named BLAH.text instead of BLAH.txt!
There are, of course, a whole bunch of ways to fix this kind of thing in linux. Previously, I'd tended to use perl one-liners. Now, I tend to use emacs.
Step 1: Open directory in dired
C-x C-f /tmp/test/
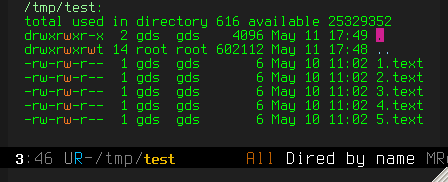
For more power, you can also open the results of a (recursive)
find or grep command with M-x find-name-dired or M-x
find-grep-dired, or you can open directories on another machine by using TRAMP.
Step 2: wdired mode
M-x wdired-change-to-wdired-mode
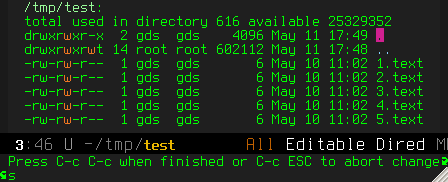
(of course, if you use this a lot, you might want to bind it to a key)
Step 3: Edit the file names like any other piece of text
I'm going to use multiple cursors, but you could use keyboard macros, regexes, regexes-with-embedded-lisp, or whatever you think best for the job in hand.
C-S-. to create the multiple cursors:
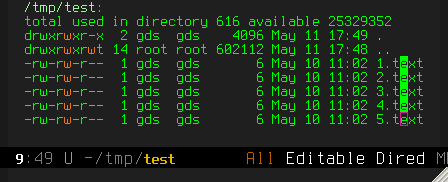
C-d to delete the offending "e" characters:
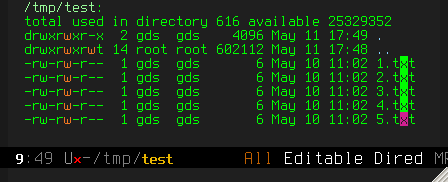
C-g to go back to just one cursor:
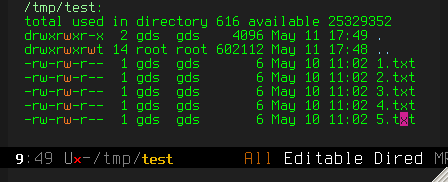
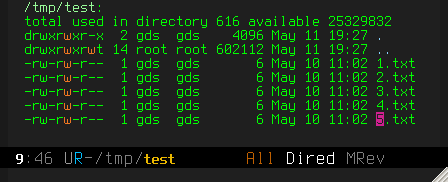
C-x C-s to "save" – to actually do the renaming of the files
(C-c C-c would also work).
Presentations with reveal.js
I've been giving a few presentations recently, and I've been really liking the reveal.js engine. When I give presentations in the browser, I can easily demo JavaScript code live, and I can fill my slides with hyperlinks which are easy for my audience to follow at the time, or later on.
But for writing presentations, I really like org-mode. And I really like typesetting maths and diagrams with LaTeX. Org-reveal to the rescue.
Maths
# -*- org-confirm-babel-evaluate: nil; -*- #+TITLE: Example Presentation #+OPTIONS: toc:nil num:nil tex:dvipng #+REVEAL_TRANS: linear #+REVEAL_THEME: simple * All the usual tricks - lists - /emphasis/ - *bold* - links * Maths \begin{displaymath} \newcommand{\sep}{\mathrel{*}} \frac{\{ P \} \texttt{code} \{ Q \} } {\{ P \sep R \} \texttt{code} \{ Q \sep R \} } \end{displaymath}
This lets you write your LaTeX math directly in your org-file. Any LaTeX will be automatically saved in a temporary file, run through the LaTeX install on your system to produce a dvi, and finally converted to a png file and included in the final web page. All from a single keyboard shortcut. The result looks something like this.
You can also forego the server-side image generation, and use
mathjax to pretty-print all our LaTeX on the client. To do this,
remove the tex:dvipng switch from your OPTIONS line, add
mathjax:t, and optionally set your org-reveal-mathjax-url
variable to the location of your server's mathjax install. You can
do this last step with a header-line such as:
# -*- org-reveal-mathjax-url: ./mathjax-MathJax-78ea6af/MathJax.js?config=TeX-AMS-MML_HTMLorMML; -*-
Drawings
LaTeX also provides a pretty good graphing tool, in the form of PGF/TikZ. To make this work properly in org-reveal, try the following:
# -*- org-confirm-babel-evaluate: nil; -*- #+TITLE: Example Presentation #+OPTIONS: toc:nil num:nil tex:imagemagick #+REVEAL_TRANS: linear #+REVEAL_THEME: simple #+LaTeX_HEADER: \usepackage{tikz} * PGF/TikZ \begin{tikzpicture} \draw [blue, fill] (0,0) rectangle (8,6); \draw [red, fill] (0,0) rectangle (4,3); \end{tikzpicture}
This time the LaTeX will be converted by the imagemagic library, which gets on better with TikZ than dvipng does. Unfortunately, it doesn't get on so well with all your carefully crafted math. At least on my machine. The result looks something like this.
Editing the LaTeX
When inserting code in an org file using babel, org provides a keyboard shortcut to allow you to edit the source block in its native mode – with syntax highlighting and helpful keyboard shortcuts and so on. Unfortunately, this doesn't work for us, since we're including the LaTeX inline, and not in babel blocks.
Fortunately, if you have my tog-mode, then you do this:
(defun gds/reveal-togs () "Enable toggling between org-mode and latex-mode." (interactive) (tog-setup (list 'latex-mode 'org-mode)))
Now, you can run M-x gds/reveal-togs, and you'll get a keyboard
shortcut C-c #, which toggles between org-mode and latex-mode.
The catch
I have not yet found a way to have LaTeX maths and tikz happily co-exist in the same org-reveal presentation. If I use dvipng to make the images, I get crisp maths and no drawings. If I use imagemagick, I get crisp drawings, but fuzzy maths images. If I use mathjax, I get nicely rendered client-side maths, and no drawings.
I'll post again if I figure it out.
Gnus for mail, lists and RSS.
I read a lot of mailing lists and RSS feeds, and I use gnus to do it. Gnus is a news and mail reader, which can speak most email protocols as well as the old NNTP used on usenet. Gnus was originally designed for usenet, and its email support came along later. For this reason, the "gnus way of doing things" isn't what you're likely to be used to from other mail readers. For example, by default gnus will show you each message precisely once. When you start gnus up, it tells you how many things you haven't read yet, and doesn't bother mentioning things you've read before. Of course, if you specifically go looking for "old messages" you can find them – it's just that they're not visible by default. This is the kind of thing that's likely to unnerve folk who're used to Gmail or Thunderbird, but it turns out to be a great way doing something like Inbox Zero. Especially since org mode can store hyperlinks to messages in gnus, so if you really need to come back to a message later, you can action it properly in your todo list, instead of using one of your mailboxes as a poor substitute for a task management program.
While I subscribe to a few mailing lists directly, I read all my RSS feeds and most of my lists using gwene and gmane. These services provide an NNTP view of RSS feeds and mailing lists respectively. From the point of view of a gnus user there's no UI difference at all between subscribing and watching gmane – but does mean someone else is responsible for archives and whatnot.
Today I happened to be reading gmane.emacs.bbdb.user when I came
across this article. That article is a reply to some other message,
and I was curious about this context. So, naturally, I hit A T,
which is gnus-speak for "show me everything in this thread". The
parent article popped up, and I read it and moved on. It was only
later that I realised that my casual A T had taken me just under
two years back in time.
I wasn't reading that list two years ago, so that was definitely a win for reading in a way that lets me tap into someone else's archive. But even if I had been reading that list two years ago in something like Thunderbird or Mutt, I'd have almost certainly archived that old message by now. So I think that little experience may have been a win for the "gnus way of doing things" as well.
Org mode spreadsheet
Let's say you're organising a meal out. You email a few friends and ask if they'd like to join you. These friends turn out to be of a particular sort, so they all email you back an estimate of the probability that they will attend. How many people should you book for at the restaurant? Org-mode to the rescue!
| Cat's conditional probabilities | Name | P |
|---|---|---|
| Gill | 1 | |
| Laurie | 0.5 | |
| Arkady | 0.5 | |
| Cara | 0.55 | |
| Ben | 1 | |
| Miranda | 0 | |
| P(Cat : Cara)= | Cath | 0 |
| 0.9 | Neil | 1 |
| P(Cat : !Cara)= | Rosie | 1 |
| 0.1 | Cat | 0.54 |
| Rachel | 1 | |
| Gareth | 1 | |
| Total | 8.09 |
Clearly we need to book a table for 8.09 people for our meal!
The key to calculating the trickier values in that org-table is the following line:
#+TBLFM: @11$3=(@11$1*(1-@5$3))+(@9$1*@5$3)::@>$3=vsum(@2$3..@>>$3)
You can read about these things in the relevant chapter of the org info manual:
(info "(org) References")
eshell and TRAMP
Ever need to copy a bunch of stuff from one user's home directory to another in linux? In bash, this might look something like:
sudo cp -R stuff ~otheruser chown -R otheruser ~otheruser/stuff
If you forget that last command, then otheruser will likely find
themselves in the madenning position of being able to see the file
you gave them, but not read and/or write it.
In eshell, one command is fine:
cp -R stuff /sudo:otheruser@localhost:
It's a tiny thing, but I like it. Note: this also works fine if you're copying between machines, over whatever transfer protocol you like.
org-time-stamp
Today I used a keyboard macro to populate one long repetitive
document from another, normalising all dates to ISO format on the
way. The trick is using M-x org-time-stamp, which can take as
input basically any date format you can think of, and outputs ISO
into the current buffer.
org-table-convert-region
Today I had a bunch of data from a spreadsheet that needed emailing to someone who may not have a spreadsheet-reading-program to hand.
In my spreadsheet reading program I highlighted the data, and copied to clipboard. In emacs, I hit:
C-x C-m(bound tognus-group-mail, to start my email)C-y(paste from clipboard)C-SPC(start highlighting)[[(a keychord I bound to "move back one paragraph")M-x org-table-convert-region
Presto: Instant ASCII-art spreadsheet in my email.
For good measure, I also used a quick keyboard macro to make a copy of the key data in a nested list format, in case my reader wasn't using a fixed width font.
Should really have thought to use org-mime-htmlize too…
Regex builder and lisp-regexes
Today, I was writing some LaTeX about some mathsey stuff I'm
doing. In one of my displaymath environments, I found that I had
something which looked a bit like this:
\func(\E{F},\E{Ls},\E{B},\E{Proto},[\E{Var}_1,\dots,\E{Var}_n]) &\triangleq & \begin{array}[t]{l} (\E{F},\fscopep)\pointsto \E{Ls} \sep {}\\ (\E{F},\bodyp )\pointsto \lambda\E{Var}_1,\dots\E{Var}_n.\E{B} \sep{}\\ (\E{F},\js{prototype} )\pointsto \E{Proto} \sep (\E{F},\protop)\pointsto \lfp \end{array}\\[\biggergap]
And which I wanted to look like this:
\func(\V{F},\V{LS},\V{B},\V{PROTO},[\V{VAR}_1,\dots,\V{VAR}_n]) &\triangleq & \begin{array}[t]{l} (\V{F},\fscopep)\pointsto \V{LS} \sep {}\\ (\V{F},\bodyp )\pointsto \lambda\V{VAR}_1,\dots\V{VAR}_n.\V{B} \sep{}\\ (\V{F},\js{prototype} )\pointsto \V{PROTO} \sep (\V{F},\protop)\pointsto \lfp \end{array}\\[\biggergap]
As any emacs or vim user will know, this calls for regular
expressions! In fact, what I wanted was to perform a
query-replace-regexp (which on my machine is bound to C-M-%)
to search for this: \\E{\(F\|Ls\|B\|Proto\|Var\)} and replace it
with this: \\V{\,(upcase \1)} (I couldn't just use .* in the
group, since there were other uses of \E that I didn't want to
change).
Unfortunately, I'm not great at writing regular expressions right
first time. For example: in the heat of the moment, I often forget the
differences between perl regexes and emacs ones. Shocking, I
know. Fortunately for me, I had previously taken the advice of
some wise old web page, and added the following to my init.el:
(global-set-key (kbd "<f8>") 're-builder)
The re-builder command pops up a little buffer into which you can
type a regex. As you type it, all matching regexes in the buffer
you came from are highlighted, so you know if you're doing it
right. And sub-groups are highlighted in a different colour to the
whole regex, so you get some feedback about the structure of the
pattern you're building. I was therefore able to hit f8, and
build my first regex piece by-piece, copy-pasting bits from my
working buffer into the regex as I pleased.
Finally I pasted my completed regex into the input of
query-replace-regexp, and made use of the nifty \,(...)
replacement pattern that emacs allows - which means "run this lisp
code".
The whole process took only a few moments.